Java 中如何查询计算 xls?
POI可以解析xls,但不提供进一步查询计算的能力,取出数据后都要自己硬写。内嵌数据库可以查询计算,但又不能解析,而且入库过程非常耗时,架构又臃肿得很。直接在xls上执行SQL是个快速轻便的好方法,但相关的开源库很少,现在都还只是雏形,实用价值不高。DataFrame类的开源库省去了解释SQL的麻烦,完成度高一些,但同时也失去了松耦合的可能性,而且计算能力远不如SQL。
计算能力够强,又能直接计算xls,而且计算代码和JAVA代码可以解耦的开源库,集算器SPL是个更好的选择。
SPL提供了简单易用的解析函数,可以轻松读取xls。比如,Excel文件的每行是一条订单记录,首行是列名,将该文件解析为二维表,只需简单写作:
=T("D:/data.xls")
函数T简单易用,默认读取第一个sheet里的数据,如果要获得更强的解析能力,应该使用函数xlsimport。比如读取名为"Orders"的特定sheet:
=file("D:/data.xlsx").xlsimport@t(;"Orders")
函数xlsimport还可以跳过标题行、从第N行读到第M行、读大文件,这里不再详述。
SPL提供了丰富的库函数,可直接完成常见的计算:
//条件查询:
=T("D:/Orders.xls").select(Amount>1000 && Amount<=3000 && like(Client,"*S*"))
//排序
=T("D:/Orders.xls").sort(Client,-Amount)";
//去重
=T("D:/Orders.xls").id(Client)";
//分组汇总
=T("D:/Orders.xls").groups(year(OrderDate);sum(Amount))";
//xlsx关联txt
=join(T("D:/Orders.xlsx"):O,SellerId; T("D:/data/Employees.txt"):E,EId).new(O.OrderID,O.Client,O.SellerId,O.Amount,O.OrderDate, E.Name,E.Gender,E.Dept)";
SPL提供了JDBC接口,JAVA代码可轻松调用,以条件查询为例:
…
Class.forName("com.esproc.jdbc.InternalDriver");
Connection connection =DriverManager.getConnection("jdbc:esproc:local://");
Statement statement = connection.createStatement();String str="=T(\"D:/Orders.xls\").select(Amount>1000 && Amount<=3000 && like(Client,\"*S*\"))";
ResultSet result = statement.executeQuery(str);
…
可以看出来SPL是解释性的计算语言,有条件做到和JAVA代码的解耦,这一点与SQL类似。事实上,SPL也支持真正的SQL语句,可降低数据库程序员的学习成本。比如上面的条件查询可以写作:
str="$select * from d:/Orders.xls where Client like'%S%'or (Amount>1000 and Amount<=2000)"
SPL支持计算代码外置,修改计算代码时无需编译,适合较复杂或频繁修改的计算,可彻底降低耦合性。做为对比,内嵌库通常不支持存储过程,而大型数据库的存储过程需要编译。这里试举一例,在各部门找出比本部门平均年龄小的员工。先将SPL算法存为脚本文件:
| A | |
| 1 | =T("Employee.xls") |
| 2 | =A1.group(DEPT; (a=~.avg(age(BIRTHDAY)),~.select(age(BIRTHDAY)<a)):YOUNG) |
| 3 | =A2.conj(YOUNG) |
再在JAVA代码中以存储过程的方式调用脚本文件:
…
Class.forName("com.esproc.jdbc.InternalDriver");
Connection connection =DriverManager.getConnection("jdbc:esproc:local://");
Statement statement = connection.createStatement();
ResultSet result = statement.executeQuery("call getYoung()");
...
对于内容不规则的xls,一般的类库都无能为力,SPL语法灵活函数丰富,可轻松解决处理。比如Excel单元格里有很多”key=value”形式的字符串,需要整理成规范的二维表,以进行后续计算。SPL代码如下:
| A | |
| 1 | =file("D:/data/keyvalue.xlsx").xlsimport@w() |
| 2 | =A1.conj().(~.split("=")) |
| 3 | =A2.new(~(1),~(2)) |
有些逻辑复杂的计算,SQL和存储过程都难以实现,SPL的计算能力更强,可轻松解决此类问题。比如:计算某支股票最长的连续上涨天数,SPL只需两行:
| A | |
| 1 | =T("d:/AAPL.xlsx") |
| 2 | =a=0,A1.max(a=if(price>price[-1],a+1,0)) |
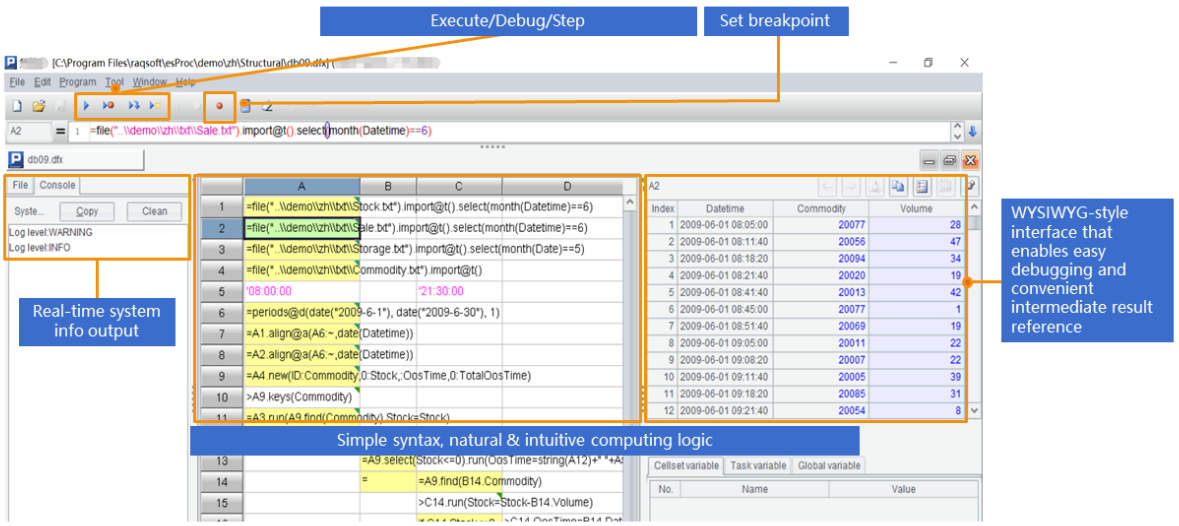
SPL提供了专业的IDE,适合设计逻辑复杂的计算,不仅具备完整的调试功能,还可以观察每一步的计算结果。
总结一下:无论计算能力,还是架构的低耦合性和轻便方面,集算器SPL都比其他开源包更具优势。
