存储过程都有什么替代方案?
关于存储过程的缺点讨论由来已久。这里我们不妨再盘点一下存储过程的主要缺点。
移植性差
移植性是指存储过程能否从原有数据库方便移植到到另一类数据库上。存储过程缺乏让存储过程语法变得很不通用,很难移植且成本高昂。
编辑调试困难
存储过程在数据库内实现,缺少有效的 IDE 环境,直到今天存储过程难以编写调试的问题仍然没有解决。
体系过于封闭
存储过程在数据库内运行只能计算数据库内数据,无法满足多样性数据源的需求。如果要计算外部数据,需要先 ETL 到库内完成,不仅浪费时间,也无法保证数据实时性,同时占用非常宝贵的数据库空间。
耦合性高
存储过程通常是为前端应用服务的,但却存储在数据库中,物理分离,维护时需要兼顾两处造成应用与数据库的紧耦合。同时,数据库的线性结构导致存储过程创建后可能被多个应用使用,又会造成应用间的紧耦合。
管理困难
数据库的结构是扁平的,而不是文件系统那样的树形结构,存储过程少的时候还好办,一旦多起来,就会陷入混乱。
安全性差
当前为应用服务的存储过程创建和修改都由应用程序员完成,这就要分配较高的数据库权限,引发数据库安全隐患,误删除等问题时有发生。
不过,不可否认的是存储过程的优点也很明显。SQL 对集合运算支持的很好,存储过程在 SQL 的基础上增加了过程控制特性,这样既可以享受到 SQL 计算的便利,还能应对复杂的计算场景。另外,存储过程在库内运算,数据不需要出库(数据库 JDBC 效率往往很低),可以减少大量的 IO 成本。
那么有没有既能享受存储过程的优点,又能规避其缺点的技术呢?
使用集算器 SPL可以替代存储过程,实现“库外存储过程”。
集算器 SPL 是一款专业的开源数据计算引擎,提供不依赖数据库的计算能力,数据库更换不需要更改 SPL 计算脚本,解决存储过程的移植性问题;简洁易用的 IDE 环境编辑调试功能齐全,算法实现更加简单;SPL 体系更加开放,可以直接使用多样数据源计算;“外置存储过程”不依赖数据库,可随应用存放解决耦合性问题;借助文件系统的树状结构进一步解决管理问题;SPL 独立数据库运行,更不会带来安全问题。
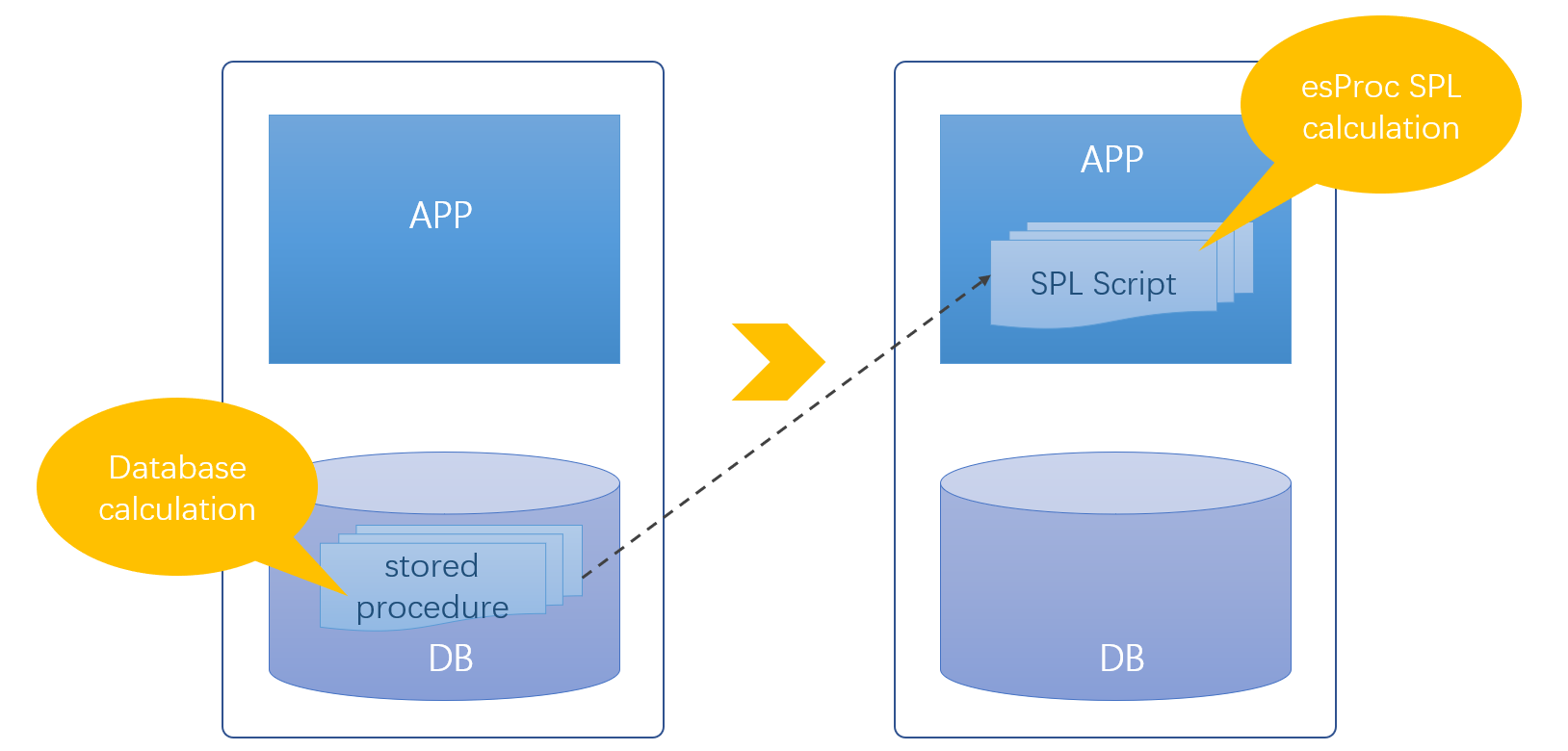
SPL 在库外实现存储过程,不再依赖数据库,这样原来绑定数据库带来的各种问题也就解决了。
库外计算与敏捷语法
SPL 提供独立数据库的计算能力。先上一段代码:
【计算目标】要找出销售额占到一半的前 n 个客户(大客户)的订单情况。
| A | |
| 1 | =file(“/opt/ods/orders.csv”).import@tc() |
| 2 | =A1.groups(customer;sum(amount):amount).sort(amount:-1) |
| 3 | =A2.sum(amount)/2 |
| 4 | =0 |
| 5 | =A2.pselect((A4=A4+amount,A4>=A3)) |
| 6 | =A2.(customer).to(,A5) |
| 7 | =A1.select(A6.pos(A1.customer)) |
通过分步的方式,先找到符合条件的大客户,再查询这些客户的详细订单信息。这些计算都是在库外完成的,甚至可以使用文件数据源。
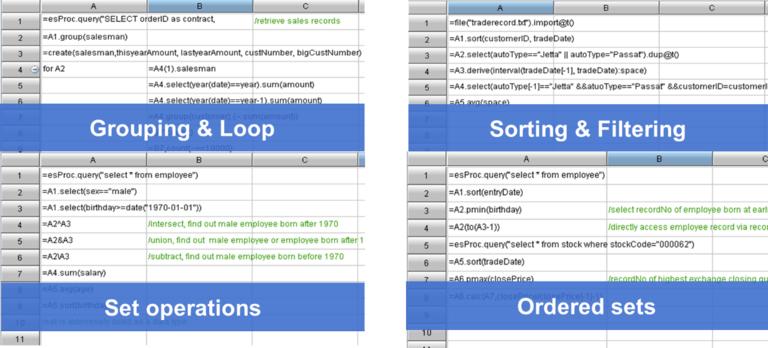
从实现的过程来看,SPL 的过程计算比存储过程更加优秀,语法也更为简洁。
SPL 提供了丰富的计算类库,可以方便地完成各类复杂计算。
易于开发调试的 IDE 环境
SPL 提供了简洁易用的开发环境,单步执行、设置断点,所见即所得的结果预览窗口…方便开发人员编写和调试代码。
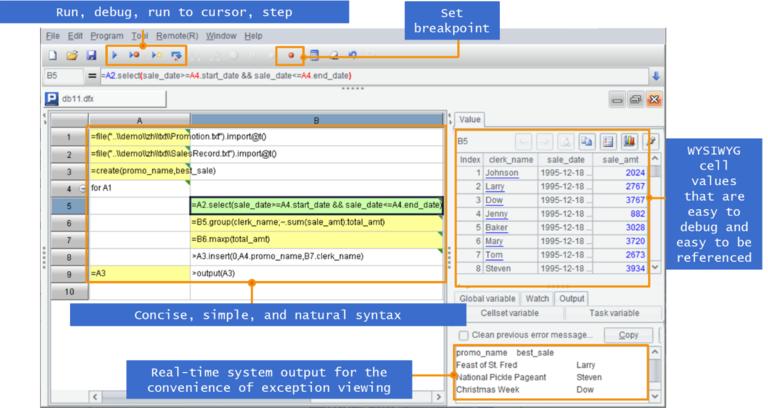
每步计算的结果都可以实时查看,相比 SQL 和存储过程不好调试要方便高效得多。
多样性数据源混合计算
相对数据库的封闭体系,SPL 更加开放,可以直接完成多源混算。SPL 目前提供了几十种数据源支持,RDB、NoSQL、CSV、Excel、HDFS、Restful/Webservice、Kafka…
可以快速连接这些数据源完成取数计算。不仅是连接取数,SPL 提供丰富的计算类库可以很方便进行异构源混合计算,实现多源关联等复杂计算。

降低耦合性,提升可管理与安全性
SPL 独立于数据库运行,解除应用与数据库的耦合性。计算脚本随应用(模块)存储在文件系统中,应用(模块)间不共用脚本文件,降低应用间耦合性。
SPL 脚本在文件系统采用树状目录管理,可以满足原来数量众多存储过程的管理需要,提升可管理性。同时不再依赖数据库,也不需要给应用程序员分配过高的数据库权限,从而提升数据库安全性。
SPL 实现的“库外存储过程”,借助 SPL 的独立计算能力、过程计算、敏捷语法易开发、开放的多样性数据源支持等特性可以实现对原有数据库存储过程的很好替代,对原有不支持存储过程的数据库也是很好地补充。
