用存储过程做数据计算的缺点
SQL 侧重结构化数据计算,但缺乏过程控制语法,相关的计算难以实现。为了弥补该缺点,存储过程(简称 SP)在 SQL 的基础上追加了这些语法。除此之外,SP 还有代码封装、防注入、动态语法等优点。但实际应用中,用 SP 做数据计算方面仍然存在诸多缺点。
耦合性高
SP 通常是为前端应用服务的,理论上两者应该在一起,从而组成完整的业务功能点。但 SP 与数据库紧密耦合,所以实践中 SP 与前端应用是物理分离的,且无法使用统一的技术路线。对于同一个功能点的 SP 和前端应用,维护其中一处,通常就要维护另一处,但两者物理上分离,维护因此变得很困难,而不统一的技术路线则加剧了这种困难。
SP 与数据库紧密耦合,反而与前端应用分离,这就容易使同一个 SP 被多个前端应用共享。时间一长,哪个 SP 到底被哪些应用调用就变成了谜团。如果某个应用的计算发生变化,面对谜团一般的共享调用关系,管理员只能新建 SP 而不敢修改原 SP。这样恶性循环下去,SP 越来越多,谜团越来越大,终将变得不可收拾。
移植困难
SP 缺乏 ANSI 2003 那样的统一规范,数据库厂商也随之放飞自我,让 SP 语法变得很不通用,很难在数据库间移植。想移植就要花费高额的开发成本,这会变成项目不可承受之重,事实上,在新数据库上重写一遍往往成本更低。SP 的难以移植出在根子上,这是管理所不能解决的问题。
管理困难
SP 的目录是扁平的,而不是文件系统那样的树形结构,脚本少的时候还好办,一旦多起来,目录就会陷入混乱。可以想象,多个项目的 SP、同一个项目不同模块的 SP、同一模块不同年份或不同版本的 SP,这些如果混杂在同一个目录下,区分起来会非常困难,除非加大管理幅度,比如按项目、模块、年代、版本命名。
安全性差
查询分析类的SP 是需要经常修改的,由于 SP 与数据库紧密结合,所以程序员每次修改 SP 代码之后,都要提交给数据库管理员,由管理员编译并分布,无疑会大大增加管理员的工作负担。所以通常的做法是:给程序员赋予高级权限,至少也是创建 SP 的权限,这样就不用频繁打扰管理员了。这样做虽然方便,但存在严重的安全隐患,因为编译 SP 的权限过大,程序员如果滥用权限,很可能误删数据,甚至删除其他应用的数据。
代码难写
SP 主要在 SQL 的基础上追加了逻辑控制语法,但并没有增强 SQL 的结构化计算能力,这就导致原来用 SQL 难写的代码,现在用 SP 同样难写,比如有序计算、分组后计算、多级关联、混合计算等。此外,SP 的调试功能近年来虽然略有起色,但离实用始终差距甚远,这就让 SP 代码更难写了。
可以看到,SP 做数据计算的确存在不少缺点,有些还很致命。那么,有什么办法可以克服这些缺点呢?
如果有外置的计算引擎,就可以解决上述问题。
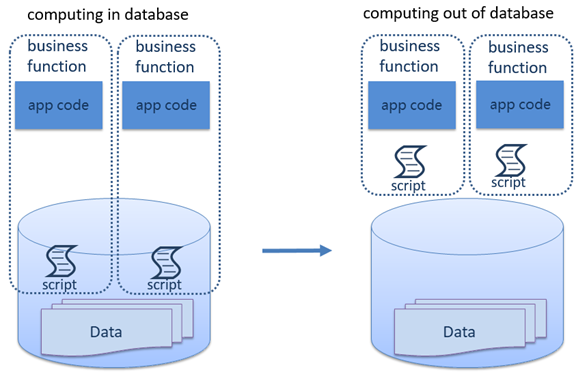
外置计算引擎应当满足以下要求:与数据库分离,能与应用集成,能解释执行,以解决耦合性高和安全性差的缺点;其计算脚本不依赖任何数据库,以解决移植困难的缺点;使用树形结构存放脚本,以解决管理困难的缺点;具有丰富的库函数和易用的调试功能,以解决代码难写缺点。
集算器 SPL 就是满足上述要求的外置计算引擎。SPL 可脱离数据库独立运行,能与应用集成,其脚本能解释执行;脚本不依赖任何数据库;使用文件系统树形目录存放脚本;具有丰富的库函数和易用的调试功能,详见 http://www.raqsoft.com/html/java-computing-layer.html
